Metadata¶
The primary purpose of OpenTSDB is to store timeseries data points and allow for various operations on that data. However it helps to know what kind of data is stored and provide some context when working with the information. OpenTSDB’s metadata is data about the data points. Much of it is user configurable to provide tie-ins with external tools such as search engines or issue tracking systems. This chapter describes various metadata available and what it’s used for.
UIDMeta¶
Every data point stored in OpenTSDB has at least three UIDs associated with
it. There will always be a metric and one or more tag pairs consisting of
a tagk or tag name, and a tagv or tag value. When a new name for one
of these UIDs comes into the system, a Unique ID is assigned so that there is
always a UID name and numeric identifier pair.
Each UID may also have a metadata entry recorded in the tsdb-uid table. Data available for each UID includes immutable fields such as the uid, type, name and created timestamp that reflects the time when the UID was first assigned. Additionally some fields may be edited such as the description, notes, displayName and a set of custom key/value pairs to record extra information. For details on the fields, see the /api/uid/uidmeta endpoint.
Whenever a new UIDMeta object is created or modified, it will be pushed to the Search plugin if a plugin has been configured and loaded. For information about UID values, see UIDs and TSUIDs.
TSMeta¶
Each timeseries in OpenTSDB is uniquely identified by the combination of its metric UID and tag name/value UIDs, creating a TSUID as per UIDs and TSUIDs. When a new timeseries is received, a TSMeta object can be recorded in the tsdb-uid table in a row identified by the TSUID. The meta object includes some immutable fields such as the tsuid, metric, tags, lastReceived and created timestamp that reflects the time when the TSMeta was first received. Additionally some fields can be edited such as a description, notes and others. See /api/uid/tsmeta for details.
Enabling Metadata¶
If you want to use metadata in your OpenTSDB setup, you must explicitly enable real-time metadata tracking and/or use the CLI tools. There are multiple options for meta data generation due to impacts on performance, so before you enable any of these settings, please test the impact on your TSDs before enabling the settings in production.
Two are available, starting with the least impact to the most.
tsd.core.meta.enable_realtime_uid- When enabled, any time a new metric, tag name or tag value is assigned a UID, a UIDMeta object is generated and optionally sent to the configured search plugin. As UIDs are assigned fairly infrequently, this setting should not impact performance very much.tsd.core.meta.enable_realtime_ts- When enabled along withtsd.core.meta.enable_tsuid_incrementingortsd.core.meta.enable_tsuid_tracking, any time a new time series arrives, an counter or flag is marked in the meta table. NOTE: Make sure to enable one of the settings below or meta-data will not be tracked in real-time.tsd.core.meta.enable_tsuid_tracking- When enabled, every time a data point is recorded, a1is written to thetsdb-metatable with the timestamp of the given data point. Enabling this setting will generate twice the number of puts to storage and may require a greater amount of memory heap. For example a single TSD should be able to achieve 6,000 data points per second with about 2GB of heap.tsd.core.meta.enable_tsuid_incrementing- When this setting is enabled, every data point written will increment a counter in thetsdb-metatable corresponding to the time series the data point belongs to. As every data points spawns an increment request, this can generate a much larger load in a TSD and chew up heap space pretty quickly so only enable this if you can spread the load across multiple TSDs or your writes are fairly small. Enabling incrementing will override thetsd.core.meta.enable_tsuid_trackingsetting. For example a single TSD should be able to achieve 3,000 data points per second with about 6GB of heap.
Warning
Watch your JVM heap usage when enabling any of the real-time meta data settings. Also watch the storage servers as write traffic may effectively double or treble.
For situations where a TSD crashes before metadata can be written to storage or if you do not enable real-time tracking, you can periodically use the uid CLI tool and the metasync sub command to generate missing UIDMeta and TSMeta objects. See uid for information.
Annotations¶
Another form of metadata is the annotation. Annotations are simple objects associated with a timestamp and, optionally, a timeseries. Annotations are meant to be a very basic means of recording an event. They are not intended as an event management or issue tracking system. Rather they can be used to link a timeseries to such an external system.
Every annotation is associated with a start timestamp. This determines where the note is stored in the backend and may be the start of an event with a beginning and end, or just used to record a note at a specific point in time. Optionally an end timestamp can be set if the note represents a time span, such as an issue that was resolved some time after the start.
Additionally, an annotation is defined by a TSUID. If the TSUID field is set to a valid TSUID, the annotation will be stored, and associated, along with the data points for the timeseries defined by the ID. This means that when creating a query for data points, any annotations stored within the requested timespan will be retrieved and optionally returned to the user. These annotations are considered “local”.
If the TSUID is empty, the annotation is considered a “global” notation, something associated with all timeseries in the system. When querying, the user can specify that global annotations be fetched for the timespan of the query. These notes will then be returned along with “local” annotations.
Annotations should have a very brief description, limited to 25 characters or so since the note may appear on a graph. If the requested timespan has many annotations, the graph can become clogged with notes. User interfaces can then let the user select an annotation to retrieve greater detail. This detail may include lengthy “notes” and/or a custom map of key/value pairs.
Users can add, edit and delete annotations via the Http API at ../api_http/annotation.
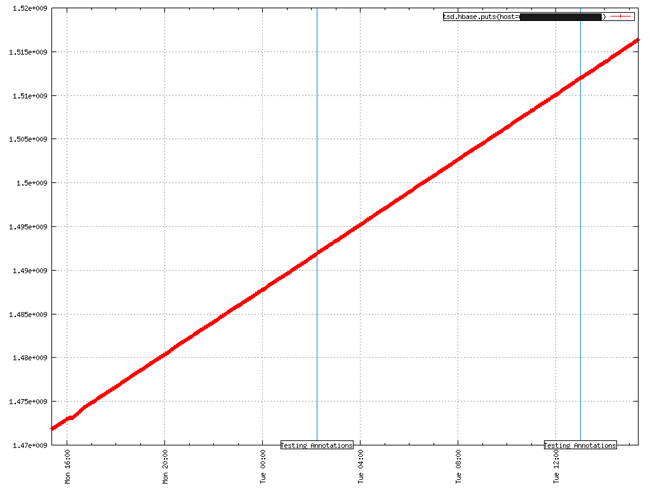
An example GnuPlot graph with annotation markers appears below. Notice how only the description field appears in a box with a blue line recording the start_time. Only the start_time appears on the graph.